
Problem: Design a system to collect, store, and query logs from thousands of services.
Key Considerations:
- Log shippers (Fluentd/Logstash) on each host
- Kafka as log buffer
- Elasticsearch for storage and full-text search
- Kibana for visualization
- Log retention policies and tiered storage
- NFRs: High ingest throughput, searchability, cost efficiencyHigh Level Architecture
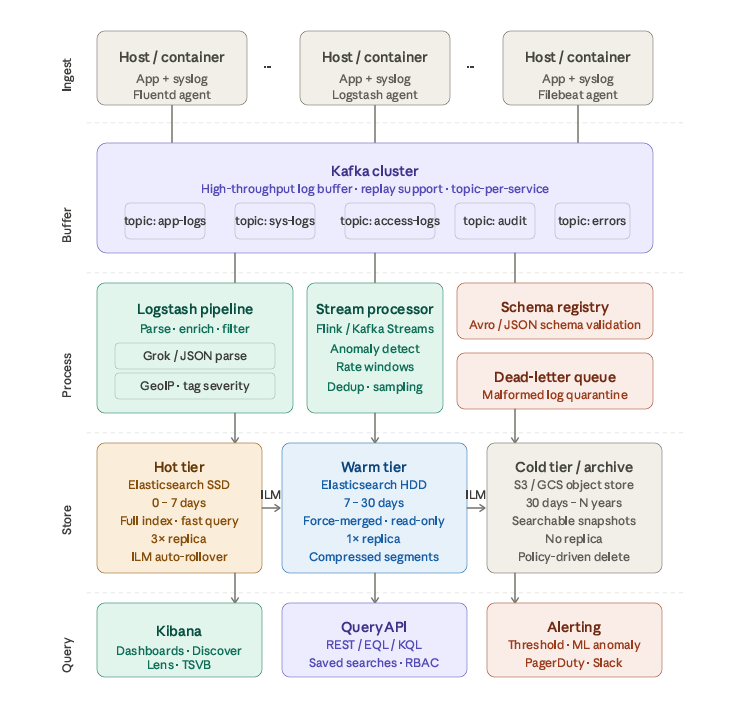
Log Aggregation System Design
Ingest layer — log shippers on every host
Each host runs a lightweight shipper (Fluentd, Filebeat, or Logstash forwarder) as a DaemonSet in Kubernetes or a sidecar per VM. The shipper tails log files, intercepts stdout/stderr, and optionally handles syslog. At this layer, the shipper does minimal work: add a host, service, and env metadata tag, then forward over a persistent TCP connection with backpressure. The heavier parsing stays downstream so the shipper can’t starve the application. Configure local disk buffering (a few hundred MB per host) so agent restarts or network blips don’t drop logs.
Kafka — durable ingest buffer
Kafka decouples ingest rate from processing rate, which is the single most important architectural decision here. At 1 TB/day across thousands of services, burst spikes happen constantly. Kafka absorbs them. Key design decisions:
- Topic-per-service-type (app-logs, sys-logs, access-logs, audit, errors) lets consumers scale independently.
- Partition count = target consumer parallelism × 2 (start at 32–64 partitions per high-volume topic).
- Retention of 24–48 hours on Kafka itself enables replay if a downstream consumer crashes mid-index.
- Producer
acks=all+ idempotency gives at-least-once delivery without duplicates at high throughput.
Processing layer
Logstash pipelines consume Kafka topics, apply Grok or JSON parsing, enrich with GeoIP, resolve usernames, tag severity levels, and drop noise (health-check endpoints, debug spam). Multiple pipeline workers on each Logstash node allow vertical scaling; horizontal scaling simply adds more Logstash nodes in a consumer group.
Stream processing (Kafka Streams or Flink) handles anything requiring stateful computation across events: anomaly detection, rate-of-error windowing, deduplication by fingerprint hash, and adaptive sampling (e.g. keep 1% of 200s but 100% of 5xxs).
A schema registry (Confluent or AWS Glue) enforces Avro/JSON schemas on producers. Malformed events route to a dead-letter topic for inspection rather than silently dropped.
Elasticsearch — tiered storage
| Tier | Storage | Retention | Replicas | Notes |
|---|---|---|---|---|
| Hot | NVMe SSD | 0–7 days | 3× | All writes here; ILM auto-rollover at 50 GB/shard |
| Warm | Spinning HDD | 7–30 days | 1× | Force-merged to 1 segment; read-only; compressed |
| Cold | S3/GCS | 30 days – N years | 0 | Searchable snapshots; on-demand mount |
Index Lifecycle Management (ILM) automates the entire transition. A daily index pattern (logs-app-2026.06.06) rolls over when it hits size or age, transitions to warm, then freezes to cold. Cost drops roughly 10× from hot to warm and 50× from hot to cold.
Shard sizing: target 20–50 GB per shard to stay in JVM heap sweet spots. Over-sharding is a common failure mode — 1000 shards of 1 GB each crushes cluster stability.
Query and visualization layer
Kibana Discover handles ad-hoc log triage; Lens and TSVB build operational dashboards. All query access goes through RBAC — teams see only their own service indices. EQL (Event Query Language) is ideal for sequence-based forensic investigation across related events.
Alerting uses threshold rules (error rate > X/min) for tactical ops and ML anomaly jobs for baseline-deviation signals, routing to PagerDuty or Slack.
NFR design choices
High ingest throughput — Kafka as the ingest shock absorber is non-negotiable. Logstash should batch bulk-index to Elasticsearch (bulk_size: 1000, flush_interval: 5s) rather than one-at-a-time.
Searchability — Elasticsearch full-text indexing on message plus keyword fields on service, host, level, and trace_id covers 95% of query patterns. Use keyword + text multi-fields for structured filtering and full-text simultaneously.
Cost efficiency — the tiered storage model is the lever. Enable best_compression codec on warm/cold. Aggressive sampling in the processing layer (drop 99% of healthy 200s) can reduce ingest volume 5–10× before storage is even a concern. Set ILM delete phases per data sensitivity class, not a single global TTL.
Hi, this is a comment.
To get started with moderating, editing, and deleting comments, please visit the Comments screen in the dashboard.
Commenter avatars come from Gravatar.